Reconocimiento de voz en Medicina
Marcial García Rojo
Servicio de Anatomía Patológica
Complejo Hospitalario de Ciudad Real
Introducción
Principales obstáculos en la utilización de los sistemas
de reconocimiento de voz Cómo funcionan los programas de reconocimiento de voz Nuevas perspectivas en los Sistemas de Información
Sanitarios
Aplicación en la Historia Clínica
Cómo utilizar eficazmente los sistemas de reconocimiento de voz
1.- Entrenar el sistema por completo
2.- Utilizar el sistema de ampliación de vocabulario antes de la utilización rutinaria
Algunas soluciones existentes en el mercado
![]()
El mayor impedimento del amplio uso de los ordenadores siempre ha sido el teclado. Este dispositivo para la entrada de datos es pesado para la mayoría de las personas y requiere alguna habilidad de mecanografiado. El reconocimiento de voz es el siguiente paso natural en la tecnología informática, y ya se dispone de algunos sistemas útiles. Esta revisión recoge algunas de las aplicaciones médicas de los sistemas de reconocimiento de voz, incluyendo un breve análisis de su funcionamiento, causas de errores y consejos para una utilización más eficaz de los mismos.
El primer sistema comercial de reconocimiento de voz de uso genérico fue DragonDictate, un sistema de habla discontinua (discrete speech).
Actualmente, los sistemas de reconocimiento utilizados se denominan "de habla continua", contienen un rico vocabulario, y pueden ser utilizados por múltiples usuarios.. El porcentaje de exactitud de los sistemas de reconocimiento de voz actuales es alto, por lo que la exactitud del reconocimiento no es un aspecto limitante en su utilización. El aspecto que limita la utilización de esta tecnología es el enfoque para integrar la funcionalidad del habla dentro de las aplicaciones.
![]()
Principales obstáculos en la utilización de
los sistemas de reconocimiento de voz [Índice]![]()
Hay muchos desafíos técnicos que han de resolverse antes de que estas tecnologías puedan ser empleadas de forma adecuada en productos y servicios en el entorno sanitario. Estos desafíos incluyen:
1.- Alto nivel de exactitud. La tecnología debe ser percibida por el usuario como muy exacta, robusta y fiable. En este sentido, los principales retos ante los que deben enfrentarse un sistema de reconocimiento de voz son:
Variabilidad lingüística: Fonética, sintaxis, semántica....
Variabilidad del usuario: Ritmo, pronunciación, inflexión, fatiga, estrés, ronquera...
Variabilidad del Canal: Ruido, cambios en el medio de transmisión...
Co-articulación: Contexto de los fonemas.
2.- Fácil de utilizar. El habla es sólo una de las varias posibles modalidades de entrada / salida de información entre un humano y una máquina, como un terminal de ordenador o un teclado de tonos en un teléfono. Por lo tanto, las tecnologías de voz deben ser transparentes para el usuario, es decir, deben tener como objetivo la naturalidad y facilidad en la interacción hombre-máquina.
![]()
Cómo funcionan los programas de
reconocimiento de voz [Índice]![]()
Para superar estos problemas, los sistemas de reconocimiento de voz incluyen tres procesos:
a) extracción de índices acústicos de la señal hablada,
b) estimación de la probabilidad de que la cadena índice fue originada por un hipotético segmento de pronunciación, y
c) determinación de la pronunciación reconocida a través de una búsqueda entre hipotéticas alternativas.
La estimación de la probabilidad de una cadena índice incluye un modelo de producción de índices por cada determinado segmento de pronunciación, por ejemplo una palabra. Los modelos ocultos de Markov se utilizan para este propósito. El sistema de reconocimiento desea encontrar la pronunciación más probable que podría originar el índice acústico observado. Esa probabilidad es el producto de dos factores: la probabilidad de que la pronunciación producirá la cadena y la probabilidad de que el hablante querrá producir la pronunciación (la probabilidad del modelo de lenguaje).
El entrenamiento de un sistema de reconocimiento de voz consiste en la lectura de un texto que proporciona al sistema no sólo un vocabulario más o menos extenso, sino un modelo de pronunciación. Terminada esta primera fase de lectura, entra el funcionamiento el entrenamiento de la red neuronal y la construcción del mencionado modelo oculto de Markov. Por último, el programa desarrollará una modelo gramatical para las secuencias de fonemas registradas. Estos dos últimos pasos, se han acortado enormemente en los últimos años gracias a la potencia de los procesadores actuales, y generalmente suponen para el usuario una espera de unos quince minutos a media hora.
Es cierto que a mayor entrenamiento del sistema (tanto en la opción inicial como durante el posterior uso del programa) se comprueba una disminución clara en el índice de errores. Sin embargo, cada sistema alcanza un plateau que oscila entre un 85% y un 95% en los sistemas comerciales actuales.
![]()
Nuevas perspectivas en los Sistemas de
Información Sanitarios [Índice]![]()
Los nuevos sistemas de información hospitalarios o de atención primaria tienen ante sí numerosos retos, algunos van siendo superados, como la mejora de la interfaz de usuario, la forma electrónica, codificación automática de procesos, gestión de solicitudes de pruebas de laboratorios, etc. Sin embargo, son muy pocos los sistemas de información en salud que integran soluciones de ayuda al diagnóstico médico o sistemas de reconocimiento de voz.
En 1993, Wulfman y colaboradores describieron tres prototipos de sistemas informáticos de registro de historias clínicas utilizando un entorno gráfico de ventanas y reconocimiento de voz continua, puesto que los sistemas comerciales tienen el inconveniente de tener un vocabulario limitado. Los prototipos confirmaron que el entorno gráfico de ventanas puede ser utilizado eficazmente para controlar e interactuar en ciertas aplicaciones de voz, pero no eran suficientes para las aplicaciones que requieren gramática muy compleja.
Una solución eficaz recientemente adoptada es la integración de un sistema de reconocimiento de voz continuo con el programa de diagnóstico de referencia médica rápida, que permite al médico incluir descripciones habladas de los hallazgos del examen físico u otras observaciones. El método se basa en la representación semántica de los hallazgos lo cual consigue minimizar el efecto de reconocimiento anómalo.
Q-MED es un sistema automático de realización de historia clínica que utiliza reconocimiento de voz continuo independiente del usuario. Permite al paciente introducir sus síntomas básicos estableciendo un diálogo con el programa. Los mecanismos de recuperación de error permiten eliminar los hallazgos que resultan de reconocimientos anómalos o interpretaciones incorrectas. La exactitud semántica media es de un 87%.
 Aplicaciones
en el Laboratorio
Aplicaciones
en el Laboratorio
La entrada por teclado de gran cantidad de datos diagnósticos es una tarea laboriosa. Cualquier error de trascripción puede pasar desapercibido para el personal no técnico empleado en la introducción de estos datos. En 1992 el Hospital General de Southampton realizó un proyecto basado en el reconocimiento de habla para la entrada "on-line" de datos de laboratorio generados en el examen microbiológico de muestras de orina. Se consideraron seis parámetros importantes para el éxito del sistema: exactitud, reconocimiento del habla, reproducibilidad, velocidad, amigabilidad para el usuario, y coste / eficacia. El sistema se comportó bien en las condiciones de prueba.
En Anatomía Patológica, los sistemas de reconocimiento de voz son bien aceptados por el personar médico y administrativos. Son utilizados para:
- Disminuir el tiempo de realización de informe.
- Optimizar la gestión del flujo de trabajo.
- Aumentar el número de muestras diagnosticadas por el mismo número de patólogos.
- Los residentes no necesitan perder el tiempo en tareas rutinarias de escritura.
- La utilización de textos preformateados y plantillas de tallado o de descripciones microscópicas (incluso con gráficos) activados por voz evita que los residentes tengan que acudir a manuales o libros o preguntar a otros patólogos sobre cómo describir y documentar las observaciones.
- Los pacientes se benefician de diagnósticos más rápidos y disminución de estancia en el hospital y de costes.
Desde 1992, se vienen utilizando dispositivos de reconocimiento de voz en la generación de informes de pruebas de diagnóstico como los estudios endoscópicos o gammagrafías con galio. Inicialmente, algunos de estos dispositivos eran controlados por personal informático. En otros casos, se han desarrollado programas informáticos propios, utilizando el modelo oculto de Markov, que incluso permiten el control del equipo (monitor, impresora, vídeo y endoscopio). Actualmente, se describe en sistemas aplicados a gastroscopias, un reconocimiento superior al 95% .
Se han realizado estudios comparativos entre el método de reconocimiento de voz frente al método convencional (grabación en cinta y trascripción) para informar radiografías. Las ventajas que el sistema de reconocimiento de voz ofrece son un menor tiempo necesario para disponer del informe (entre un 25% y un 73 % más rápido, según los estudios consultados) y una mejor valoración subjetiva de los resultados por parte del médico. Los datos obtenidos mediante el informe de voz en la radiografía son útiles no sólo para reducir el tiempo medio en la confección del informe sino para mejorar la calidad del informe reduciendo tanto los errores gramaticales como de trascripción.
También se emplean sistemas activados por voz para realizar búsquedas de imágenes de referencia de mamografía en bases de datos, tanto en formación continuada como en la interpretación rutinaria de casos.
Aunque no es el objetivo de esta revisión, conviene mencionar como ejemplo el desarrollado de redes neuronales multicapa, entrenadas y probadas utilizando palabras aisladas pronunciadas por pacientes con disartria. Estos sistemas tienen un rendimiento superior incluso que el ser humano en la comprensión de estos enfermos.
En un estudió reciente se comprobó que el método de entrevista automatizado utilizando un programa de reconocimiento de voz a través de teléfono era una herramienta adecuada para el screening de la depresión. Los resultados sugerían que el tiempo de latencia de respuesta verbal se correlacionaba positivamente con las puntuaciones de depresión.
Por último, la activación de equipos quirúrgicos mediante comandos de voz (con frecuencia, independientes del usuario) facilita la cirugía robotizada.
![]()
Cómo utilizar eficazmente los sistemas de
reconocimiento de voz [Índice]![]()
Actualmente, en España, casi todos los servicios médicos que disponen de sistemas de reconocimiento de voz utilizan soluciones comerciales de ámbito general a las que, ocasionalmente puede añadirse un vocabulario médico especializado. En todo caso, el vocabulario médico disponible en español con frecuencia no es adecuado para una especialidad determinada, por lo que las siguientes instrucciones tienen como objetivo ampliar el modelo lingüístico del sistema de reconocimiento de voz para conseguir una mínima tasa de errores:
Aunque los programas comerciales a los que nos referimos permiten realizar una inscripción o entrenamiento "abreviados", conviene realizar este entrenamiento de forma completa cuando sea posible, para alcanzar el máximo índice de reconocimiento con nuestra propia entonación. Sin embargo, realizar dos veces o más la inscripción no proporcionará apenas ninguna ventaja adicional.
2.- Utilizar el sistema de ampliación de vocabulario antes de la utilización rutinaria
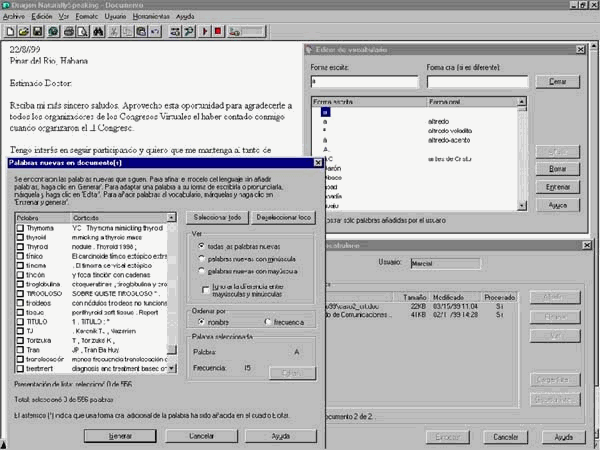
Este paso es imprescindible en los programas que no incorporan vocabulario médico, pues de esta forma el programa no sólo aprenderá las palabras nuevas sino cómo las pronunciamos cada uno. Lamentablemente es un proceso tedioso, que supone la recogida de un texto (por ejemplo, varias historias clínicas), entre las que el sistema selecciona las palabras nuevas y nos obliga a pronunciarlas una a una.
A pesar de realizar este paso previo, comprobaremos que el sistema falla en las palabras que le hemos añadido, pues con frecuencia, al utilizar el generador de vocabulario, no se dispone del contexto adecuado en que se encuentra esa palabra. Sin embargo, al haberla añadido previamente al sistema, aparecerá entre el listado de las opciones de corrección, por lo que la corrección del texto será mucho más rápida. Una vez corregida la palabra en su nuevo contexto, será fácilmente reconocida la próxima vez que la necesitemos.
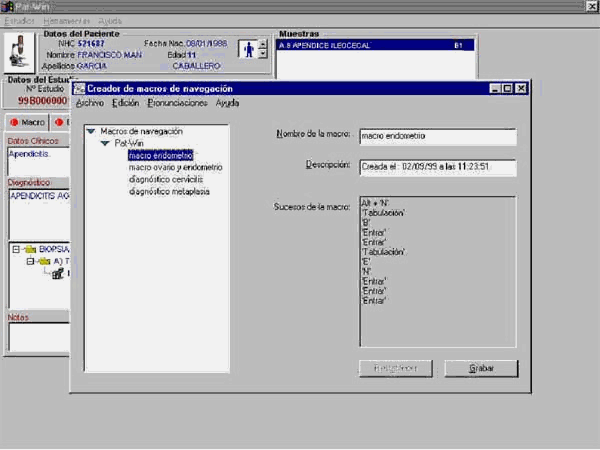
Existen varios tipos de macros:
F Macros de texto o de dictado. Nos permite sustituir una palabra o secuencia de palabras determinada por una o varias frases completas. Por ejemplo, podemos decir "E3" y el programa escribirá "Radiografía lateral de tórax con campos pulmonares sin hallazgos significativos....". La ventaja de este sistema respecto al que ya incorporan muchos sistemas de información (textos preformateados) es que no necesitamos escoger la opción deseada de ninguna lista ni tenemos que abrir ningún cuadro de diálogo.
F Macros de comandos o de navegación. Es quizá el recurso más interesante que deberían incluir todos los sistemas de reconocimiento de voz. Nos permite grabar una secuencia completa de eventos (generados tanto mediante teclado como mediante el ratón) y posteriormente repetirlos con sólo pronunciar un comando. Por ejemplo, podemos abrir la sección de solicitudes de laboratorio de nuestro programa informático de historias clínicas, seleccionar la opción de ir a un enfermo determinado (el último, el primero, o simplemente seleccionar la historia que ya estábamos editando), escribir las peticiones habituales, como hemoglobina, hematocrito o recuento sanguíneo, luego mandar a imprimir la solicitud y volver a la sección en que nos encontrábamos esto. Pues bien, una tarea rutinaria como ésta, aunque sólo la vayamos a repetir dos veces al día, comprobaremos con agrado que podemos ahorrárnosla si grabamos esta secuencia con nombre determinado (por ejemplo, "Fórmula y Recuento") que será todo lo que necesitemos pronunciar. Además, las tareas de impresión, envío de fax, copiar y pegar texto entre diversas aplicaciones, etc., pueden verse enormemente beneficiadas de estas macros de comandos.
F Macros de programas. Son muy similares a las anteriores pero incluye la ejecución de rutinas de programas (DLL, control ActiveX, etc.)
F Macros estructuradas (plantillas). Si el texto que queremos completa con un solo comando de voz es complejo, con múltiples variables (la edad, el peso del paciente, etc.), nos veremos obligados a utilizar macros estructuradas, que permiten diseñar en un procesador de texto todos los párrafos que han de constituir el texto completo, incluyendo aquellas variables que el programa pedirá al ejecutar esta macro.
![]()
Algunas soluciones existentes en el
mercado [Índice]![]()
F Philips es una de las empresas pionera en el desarrollo de sistemas de reconocimiento de voz, aunque inicialmente esta empresa no diseñaba directamente aplicaciones en este sector, sino que su motor de reconocimiento era utilizado por otras empresas (como Cortex Management Systems). Speech Magic, un producto de Philips incluía un vocabulario de 64.000 palabras, con un vocabulario auxiliar de 270.000 vocablos. El sistema se basaba en un ordenador que actuaba de servidor de reconocimiento de la voz, que sirvió para diseñar el primer sistema de reconocimiento de voz continua en los laboratorios y que también fue aplicado a radiología y otras especialidades médicas. Su exactitud es de un 95%. Además, Philips dispone de diversos accesorios, como SpeechMike ( un micrófono con trackball y altavoz). Otro de sus productos, FreeSpeech incluye 30.000 palabras en su vocabulario. Este sistema está disponible en Español para usuarios domésticos (Philips FreeSpeech 2000) y su precio ronda las 25.000 pesetas.
Gracias a la integración con sistemas de información hospitalarios, como Broca ( de Cortex), basta decir por ejemplo "Comenzar descripción" para que el programa abra la descripción de un informe, escriba el texto dictado en la sección correspondiente y lo grabe directamente en el sistema de información hospitalario.
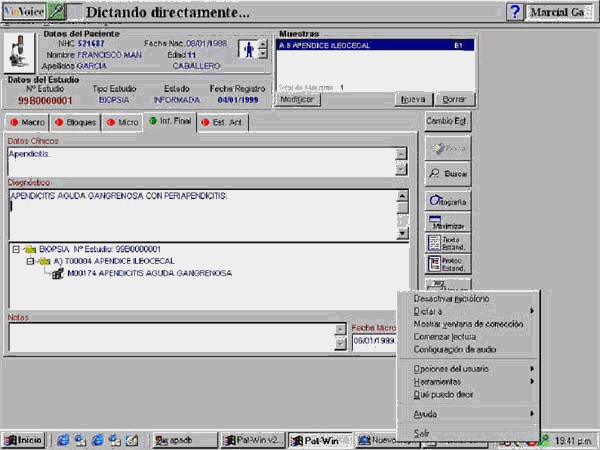
F IBM dispone de soluciones tanto para el usuario doméstico como sistemas muy especializados (estos últimos sólo en Inglés), como IBM MedSpeak. En su versión para Anatomía Patológica, por ejemplo, incluye un vocabulario de 25.000 palabras de la especialidad. Permite personalizar las plantillas de texto y puede integrarse en cualquier aplicación gracias a la utilización de controles Active-X y una interfaz con HL-7. IBM ViaVoice es el único producto que incluye un vocabulario médico en Español (de 38.000 vocablos), por un precio aproximado de 34.000 pesetas; además, permite un control total del ordenador (excepto los cuadros de diálogo). Su exactitud es similar al resto, de un 95% y el tiempo de entrenamiento estimado es de 30 minutos. Algunas empresas norteamericanas de desarrollo informático médico, como Dynamic Healthcare Technologies y Talk Technologies incluyen el sistema de IBM en sus aplicaciones.
En aquellos sistemas informáticos que no contienen IBM ViaVoice integrado, podemos dictar directamente en los recuadros de texto correspondientes:
F Lernout & Hauspie (L&H) dispone de una enorme experiencia en reconocimiento de voz, con soluciones globales como L&H Kurzweil Clinical Reporter, con vocabulario médico (en inglés), plantillas, un control total del sistema y, sobre todo, porque incluye una base de conocimientos amplísima (por ejemplo, en cáncer incluye el Rosai Cancer Checklist). Su única limitación es su alto coste (un millón de pesetas por licencia). Una solución más asequible, aunque tampoco está disponible en Español, es L&H Voice Xpress for Medicine, un programa que se integra fácilmente con Microsoft Word (la mayoría lo hacen), incluye vocabulario médico específico para varias especialidades médicas y macros de texto. El precio oscila entre 80.000 y 250.000 ptas. Los sistemas de L&H permiten disponer de un vocabulario auxiliar de hasta 640.000 palabras y, aunque requieren un hardware potente, puede alcanzar una tasa superior a las 140 palabras por minuto.
F Dragon Systems dispone probablemente del mejor motor de reconocimiento de voz que existe en el mercado. Es el único que alcanza una exactitud de un 95-98%. Sin embargo, carece de las alianzas de sus competidores más directos (Philips, IBM y L&H), por lo que hasta ahora este sistema de reconocimiento de voz está integrado en muy pocos sistemas de información sanitarios (Voice Automated & Articulate Systems es de los pocas empresas que lo incluyen). Naturally Speaking es un excelente producto disponible en español, a un precio similar al IBM ViaVoice, aunque carece de la posibilidad de realizar macros de texto o de comandos o de navegar por los menús de los programas. Recientemente, Dragon Systems ha lanzado Naturally Speaking Medical Suite, no disponible en español, que incluye un vocabulario médico de hasta 55.000 vocablos y 240.000 de respaldo. Además, Dragon Command Wizard es una asistente que permite la creación de macros e incluso dispone de un lenguaje de comandos. El sistema permite un dictado de hasta 160 palabras por minuto.
F Dictaphone Corporation ha diseñado en Estados Unidos sistemas de información pensados para ser utilizados específicamente mediante comandos de voz, e incorpora la tecnología de Philips (Speech Magic) o de IBM (como Boomerang™, un programa para el envío de ficheros de voz utilizando IBM ViaVoice)
A pesar de las mejoras de estos últimos años, en un reciente estudio norteamericano, sólo un 7,5% de los pediatras utilizan sistemas de reconocimiento de voz en la confección de sus informes.
El pobre rendimiento de estos programas frente al texto desconocido no se debe a una incompetencia del sistema sino a la gran cantidad de jerga técnica en el ámbito de los escritos médicos. Para conseguir un rendimiento aceptable sugerimos que se extienda la fase de entrenamiento o, preferiblemente, diseñar aplicaciones o vocabularios distintos para cada especialidad médica. La gran capacidad de aprendizaje hace al sistema un serio candidato para sustituir los métodos de trascripción clásicos.
El coste de los sistemas de reconocimiento de voz disminuye constantemente, por lo que cada vez son más infrecuentes los sistemas servidores de reconocimiento y se tiende a la implantación de sistemas personales, que, preferiblemente, deberán ser adaptados a la especialidad de cada médico.
Los sistemas de reconocimiento de voz en dispositivos inalámbricos (como Dragon Naturally Speaking Movible) permitirán una mayor independencia del profesional a la hora de redactar sus informes.
![]()
Principales referencias [Índice]![]()
F http://home.nycap.rr.com/voice/
Voice Recognition For Pathology. Michael Riben MRIBEN1@NYCAP.rr.comF Borowitz, SM. Computer-Based Speech Recognition as a Replacement for Medical Transcription. Pediatric Research 1999; 45:120A.
F Imhoff M. Acquisition of ICU data: concepts and demands. Int J Clin Monit Comput 12; : 22-37.
F Teplitz C, Cipriani M, Dicostanzo D, Sarlin J. Automated speech-recognition anatomic pathology (ASAP) reporting. Sem Diagn Pathol 1994; 11: 245-252
F Tischler AS, Martin MR. Generation of surgical pathology reports using a 5,000-word speech recognizer. Am J Clin Pathol 1989; 92 (Suppl 1): S44-S47.
F Hogan, R. Dragon NaturallySpeaking. JAMA Volume 280(15) 21 October 1998 pp 1369-1370.